The last time we wrote about replacing Sonnet, the plan was ambitious: pool four machines into a heterogeneous cluster, run Kimi K2.6 at Q8, and measure whether open-weight models could cross the bar for long-context agentic work. That was April 23. Six weeks later, the landscape looks different — and the strategy has shifted.
The cluster never materialized. Not because the hardware couldn't do it, but because the software layer — heterogeneous Exo backends, MLX-CUDA interop on Blackwell, and disaggregated prefill/decode across Apple+NVIDIA — remains deeply immature. The people actually doing this work are reporting results that range from "technically runs" to "slower than one machine alone." The bandwidth math from April still holds: Thunderbolt 5 at ~10 GB/s vs M3 Ultra's on-package ~800 GB/s means any tensor-parallel split across the seam pays a ~100× tax. The Sparks would make things slower, not faster.
So we shelved the cluster and took a different approach: replace Sonnet from the cloud side, and keep testing local models until something sticks.
The single biggest change since April: we moved a massive share of tokens to DeepSeek V4 Pro on Fireworks. At $1.74/MTok input and $3.48/MTok output, V4 Pro delivers frontier reasoning quality at a fraction of Anthropic's API pricing. It's become Bandit's main agent, and the dollar figures are hard to argue with.
V4 Pro isn't a Sonnet replacement in feel — it's more methodical, less conversational. But for the work that matters (code generation, tool orchestration, infrastructure triage) it is genuinely competitive. The 1M token context window eliminates the rationing problem, and the reasoning field gives us visibility into what the model is thinking before it acts.
Sonnet still earns its keep for interactive defaults and front-end work where taste matters. But the ratio has flipped: most tokens now flow through V4 Pro, not Anthropic.
Below is our daily Anthropic API spend from early April through May 1 — the period before and during the V4 Pro migration. Every color represents a different Claude model. The tallest bars hit $500–$600 in a single day.
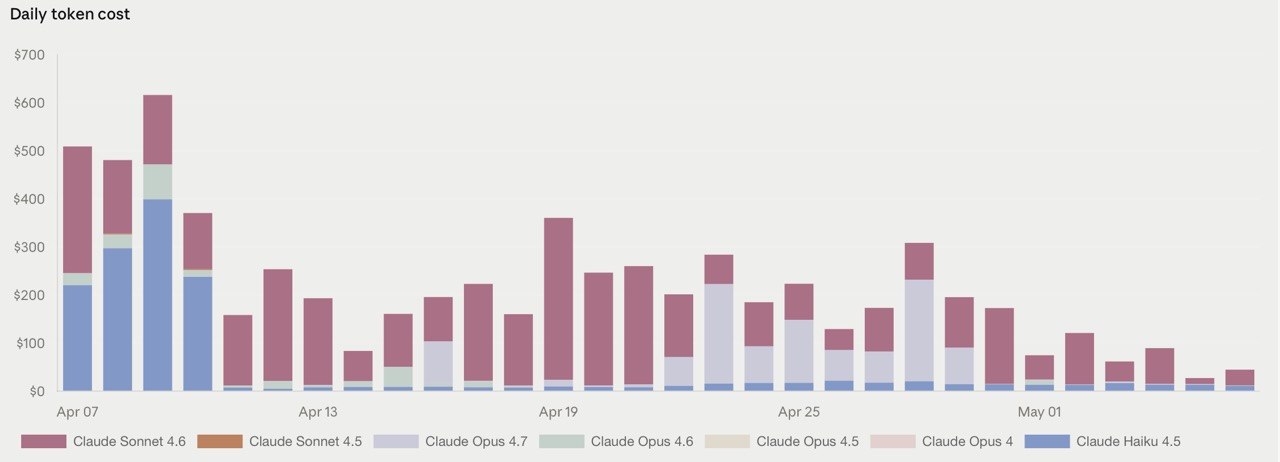
Running the numbers: approximately $6,130 across 24 tracked days in April, averaging $255/day. The early-April peak of $610 on April 9th is especially sharp — that's a single day of Claude API calls costing more than a month of V4 Pro at our current usage levels. Weekend dips are visible (April 13 at $90, April 20 at $250), but the overall burn rate is punishing.
The May 1 bar tells the transition story: $80. That's the first day where V4 Pro handled most of the workload, and Anthropic spend cratered. V4 Pro at $1.74/MTok input and $3.48/MTok output is roughly 3–4× cheaper per token than Sonnet, and 8–10× cheaper than Opus. The chart makes the math visible.
And here's where those tokens went instead. Below is our Fireworks serverless dashboard for the same period, showing V4 Pro token consumption:
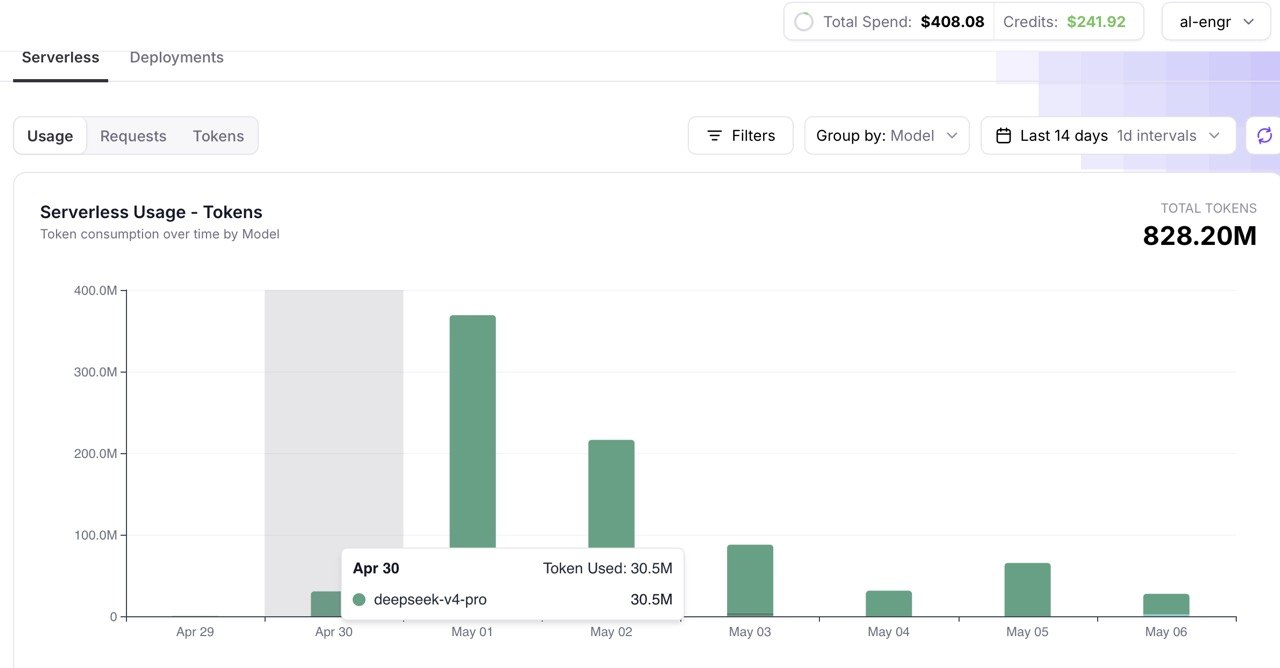
The numbers: 828.2 million tokens over ~8 days, totaling $408.08. That's $51/day. Extrapolated to a full month, V4 Pro runs about $1,530/month at our usage levels — compared to the $6,130/month we were paying Anthropic. That's a 75% reduction in API spend, with no degradation in agent capability for the heavy-lifting tasks.
The peak day (April 30, at 30.5M tokens) likely represents a full shift of main-agent traffic — blog updates, infrastructure triage, code generation — all running on V4 Pro. At Anthropic's Sonnet pricing, that single day would have cost roughly $90–130 on its own.
We've also run an accidental model evaluation gauntlet — five local models tried and failed as main agent. Here's the scorecard:
| Model | Active Params | Result | Why It Failed |
|---|---|---|---|
| Qwen3.5-397B-A17B | 17B | ✅ Production | Hasn't failed. Handles 64K prompts, multi-step blog updates, complex tool chains. The current local king. |
| DeepSeek V4 Flash (4-bit) | 13B | ❌ Failed | Lost coherence on multi-step tasks. Blog update pipeline fell apart. GPU timeout crash required prefill-step-size workaround. |
| Qwen3.6-35B-A3B | 3B | ❌ Failed | Fastest model in the fleet (~54 tok/s) but only 3B active — tool calls become inconsistent mid-pipeline. So close. |
| GLM 5.1 | — | ❌ Failed → 🔄 Retesting | Couldn't serve on the fleet at all. Dead on arrival. New model weights available — planning retest. |
| Kimi K2.6 (Q2_K_XL) | 32B | ⚠️ Too Slow | Can do the work — successfully edited this blog with active-memory fixed. But 99K-token prompts take ~38 min just to process at 43 tok/s on llama.cpp. Times out before generation begins on sustained sessions. Not practically viable on this serving stack. |
The Kimi K2.6 story is a lesson in chasing bottlenecks. At 32B active parameters, it sat dead in the water for weeks — three serving stacks, context overflow bugs, and the active-memory reasoning trap all stacking on top of each other. Once we isolated the active-memory fix (pin gemini-flash for recall), Kimi woke up and successfully edited this blog post — a genuine turnaround. We bumped ctx-size from 131K to 164K to give it breathing room, and the model was ready.
Then we hit a bottleneck that isn't about context, reasoning, or tool use. It's about speed.
After the 164K ctx-size bump, we gave Kimi K2.6 40 minutes as main agent to update this blog post. It didn't get there. The llama-server logs on M3 Ultra tell the story:
slot update_slots: id 0 | task 61 | n_tokens = 71681 ... → cancel task, id_task = 61 slot update_slots: id 0 | task 72 | new prompt, n_ctx_slot = 163840, task.n_tokens = 98972 slot update_slots: id 0 | task 72 | n_tokens = 81921 ... → cancel task, id_task = 72 slot update_slots: id 0 | task 78 | new prompt, n_ctx_slot = 163840, task.n_tokens = 98972 slot update_slots: id 0 | task 78 | n_tokens = 88065 ... → cancel task, id_task = 78 srv update_slots: all slots are idle
Three consecutive tasks. Each one loaded with ~99,000 tokens of system prompt, tool definitions, and conversation history. Each one cancelled before reaching generation.
The math is brutal:
The model spends nearly its entire 40-minute window just digesting the prompt. By the time it's ready to generate, there's barely enough time for one tool call. When the request times out, OpenClaw retries — and the cycle starts over from scratch. Another 99K tokens, another 38 minutes, another cancellation.
This isn't a model capability failure. Kimi K2.6 at 32B active parameters can do the work — it proved that on shorter sessions. The problem is that llama.cpp's prompt processing throughput on Q2_K_XL is too slow for sustained main-agent workloads where the prompt grows to 100K tokens. Every tool call adds more context, and every retry starts the clock over.
Here's a complication that makes the local model quest harder than it looks: even if we found a local model that handled tool chains perfectly, we'd still have a security problem.
Cloud models from Anthropic and OpenAI ship with constitutional AI training, harmlessness fine-tuning, and infrastructure-level guardrails. A raw GGUF does not. If you hand an open-weight model your filesystem, your Docker socket, and a shell, you are trusting it not to exfiltrate data, execute destructive commands, or follow injected instructions hidden in web pages it fetches.
This isn't theoretical. OpenClaw agents routinely fetch untrusted web content, read emails, and process external data. Sonnet and V4 Pro have been hardened against prompt injection at the training and infrastructure level. A Q2 quantization of a base model has none of that.
The obvious countermeasure — a smaller model that screens prompts before they reach the agent — doesn't work well enough yet. It adds latency, introduces its own false positives, and the screening model itself is vulnerable to the same injection vectors. This is an unsolved problem, and it's a real argument against rushing local models into main agent roles.
While evaluating cloud models for the main agent role, we tried Grok 4.3 to update this very blog post. It failed — but not for the reasons our local models failed. The session terminated in 2.8 seconds, before any real agent work could happen.
The culprit was a reasoning_content bug in OpenClaw's active-memory plugin. Active memory runs a blocking sub-agent before the main reply to inject relevant memory into the prompt context. It inherits the session's model by default. When that model is a reasoning model (like Grok 4.3 with reasoning: true), the model outputs its answer in reasoning_content — but the plugin reads from content. Empty content → empty summary → failover logic surfaces an error → session dies instantly.
This is the exact same bug that bit us with Kimi K2.6's OpenClaw config, just manifesting at a different layer. The fix: pin a dedicated non-reasoning model for active memory recall. We set model: "google/gemini-3-flash" in the active-memory plugin config, bypassing the session model entirely. Gemini Flash is fast (sub-second), free-tier, and non-reasoning — a clean fit for the narrow memory-search task.
content responses. The fix should happen upstream (plugins should fall back to reasoning_content when content is empty), but pinning a dedicated recall model is a pragmatic workaround until that lands.Update (May 6, 2026): After pinning the active-memory plugin to google/gemini-3-flash, Grok 4.3 is now successfully running as the main agent. This very blog post — including the cost charts, V4 Pro comparison, and retest notes — was fetched, edited, and deployed by Grok 4.3. The reasoning_content incompatibility is bypassed, and the model is handling multi-step agentic tasks without issue.
The practical strategy, for now:
The quest hasn't failed. It's just on a longer timeline than we thought in April. The hardware is ready. The models are getting closer. The bottleneck has shifted from model capability to serving infrastructure — and that's actually progress. The security story is the part that still needs work.
© 2026 J&M Labs — James Meadlock & Bandit 🦝